こんにちは、いーさんです。
前回の記事ではスタック(Stack)について解説しましたが、今回はもう1つの基本的なデータ構造である「キュー(Queue)」について、paizaで学んだことをまとめます。
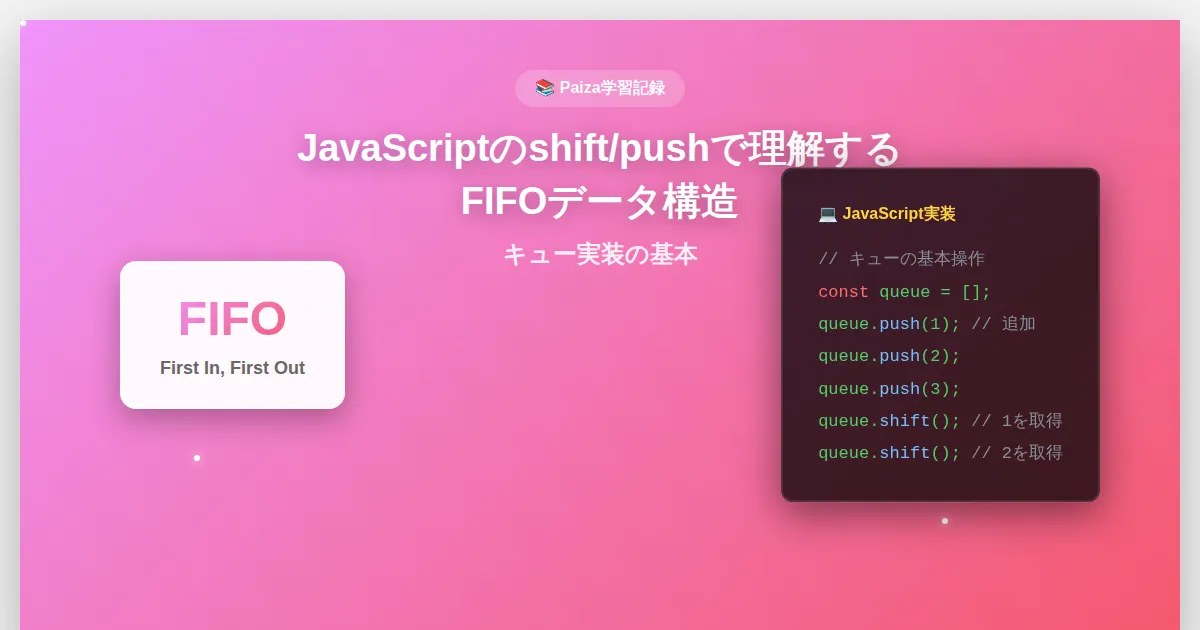
キューは「先入れ先出し(FIFO: First In First Out)」という特徴を持つデータ構造で、スタックとは逆の動きをします。こちらも日常生活でよく見かける構造なので、イメージしやすいと思います。
キューとは?
キューをイメージで理解する
キューは、一番最初に入れたデータが一番最初に取り出されるデータ構造です。
身近な例:レジの行列
想像してください。スーパーのレジで、お客さんが順番に並んでいるとします:
- 最初にAさんが並ぶ
- 次にBさんが並ぶ
- 次にCさんが並ぶ
- 最後にDさんが並ぶ
さて、誰から会計しますか?
一番最初に並んだAさんから順番に会計しますよね。

これがキューです。
ポイント:
- 最初に並んだ人が最初に会計できる
- 最後に並んだ人が最後に会計する
- 途中から割り込めない(順番を守る)
FIFO(First In First Out)とは
キューの動きを表す言葉です。
- First In(ファースト・イン):最初に入った
- First Out(ファースト・アウト):最初に出る
覚え方: 「先入れ先出し」= 先に入ったものが先に出る
スタックとの違い:
- スタック(LIFO):最後に入れたものが最初に出る(ブロックの積み重ね)
- キュー(FIFO):最初に入れたものが最初に出る(レジの行列)
キューの基本操作
キューには主に2つの操作があります。レジの行列で考えると分かりやすいです。
1. enqueue(エンキュー):列に並ぶ
キューの末尾にデータを追加します。
レジの例:
最初:誰も並んでいない
↓ Aさんが並ぶ(enqueue)
[Aさん]
↓ Bさんが並ぶ(enqueue)
[Aさん][Bさん]
↓ Cさんが並ぶ(enqueue)
[Aさん][Bさん][Cさん]
↓ Dさんが並ぶ(enqueue)
[Aさん][Bさん][Cさん][Dさん]
JavaScriptでの実装:
let queue = [];
queue.push("Aさん"); // ["Aさん"]
queue.push("Bさん"); // ["Aさん", "Bさん"]
queue.push("Cさん"); // ["Aさん", "Bさん", "Cさん"]
queue.push("Dさん"); // ["Aさん", "Bさん", "Cさん", "Dさん"]
JavaScriptでは push() を使います。
2. dequeue(デキュー):会計する
キューの先頭からデータを取り出します。
レジの例:
[Aさん][Bさん][Cさん][Dさん]
↑
Aさんの会計をする(dequeue)
↓
[Bさん][Cさん][Dさん]
↑
次はBさん
JavaScriptでの実装:
let queue = ["Aさん", "Bさん", "Cさん", "Dさん"];
let お客さん = queue.shift(); // お客さん = "Aさん", queue = ["Bさん", "Cさん", "Dさん"]
let お客さん2 = queue.shift(); // お客さん2 = "Bさん", queue = ["Cさん", "Dさん"]
JavaScriptでは shift() を使います。
重要なポイント:
shift()は取り出したデータを返してくれる- 取り出したデータはキューからなくなる(削除される)
- 先頭からしか取り出せない(割り込み禁止)
スタックとキューの違い
視覚的に比較してみましょう。
スタック(LIFO)- ブロックの積み重ね
取り出す → [赤][紫][緑][青][黄][オレンジ] ← 積み上げる
↑
最後に積んだ赤が
最初に取れる
let stack = [];
stack.push("オレンジ");
stack.push("黄");
stack.push("青");
stack.pop(); // "青"が出る(最後に入れたもの)
キュー(FIFO)- レジの行列
会計する ← [Aさん][Bさん][Cさん][Dさん] ← 並ぶ
↑
最初に並んだAさんが
最初に会計できる
let queue = [];
queue.push("Aさん");
queue.push("Bさん");
queue.push("Cさん");
queue.shift(); // "Aさん"が出る(最初に入れたもの)
比較表
| 特徴 | スタック(Stack) | キュー(Queue) |
|---|---|---|
| データ構造 | LIFO(後入れ先出し) | FIFO(先入れ先出し) |
| 追加 | push() | push() |
| 取り出し | pop() | shift() |
| 取り出す場所 | 末尾(上) | 先頭(前) |
| イメージ | ブロックの積み重ね | レジの行列 |
JavaScriptでのキュー実装
JavaScriptでは、配列のメソッドを組み合わせてキューを実装できます。
基本的な実装
// キューの初期化
let queue = [];
// データを追加(enqueue)
queue.push("Apple");
queue.push("Banana");
queue.push("Cherry");
console.log(queue); // ["Apple", "Banana", "Cherry"]
// データを取り出す(dequeue)
let fruit = queue.shift();
console.log(fruit); // "Apple" ← 最初に入れたもの
console.log(queue); // ["Banana", "Cherry"]
キューが空かどうかチェック
if(queue.length === 0){
console.log("キューは空です");
} else {
console.log("キューにデータがあります");
}
先頭のデータを見る(取り出さない)
let queue = [1, 2, 3];
// 最初の要素を見るだけ(削除しない)
let front = queue[0];
console.log(front); // 1
console.log(queue); // [1, 2, 3] ← 変わらない
paizaで解いた問題:2つのキュー
paizaの「2つのキュー」という問題に取り組みました。
問題概要
2つのキュー(que1とque2)を管理します。Q個のクエリが与えられ、各クエリは以下のいずれかです:
- クエリ 1 1 N:que1にNを追加
- クエリ 1 2 N:que2にNを追加
- クエリ 2 1:que1から取り出して出力
- クエリ 2 2:que2から取り出して出力
- クエリ 3:que1とque2のサイズを出力
実装したコード
const Q = Number(lines[0]);
que1 = [];
que2 = [];
for(let i = 0; i < Q; i++){
let query = lines[i+1].split(" ");
if(query[0] === "1" && query[1] === "1"){
// que1に追加
que1.push(query[2]);
} else if(query[0] === "1" && query[1] === "2"){
// que2に追加
que2.push(query[2]);
} else if(query[0] === "2" && query[1] === "1"){
// que1から取り出し
console.log(que1.shift());
} else if(query[0] === "2" && query[1] === "2"){
// que2から取り出し
console.log(que2.shift());
} else {
// 両方のサイズを出力
console.log(que1.length, que2.length);
}
}
コードの解説
1. 2つのキューの初期化
que1 = [];
que2 = [];
2つの空配列を用意します。これがそれぞれのキューになります。
2. クエリの分解
let query = lines[i+1].split(" ");
クエリを分解します:
"1 1 5"→["1", "1", "5"]"2 1"→["2", "1"]"3"→["3"]
3. enqueue操作(追加)
if(query[0] === "1" && query[1] === "1"){
que1.push(query[2]);
} else if(query[0] === "1" && query[1] === "2"){
que2.push(query[2]);
}
- クエリタイプが「1」なら追加操作
- 2番目の数値でどちらのキューか判定
push()で末尾に追加
4. dequeue操作(取り出し)
else if(query[0] === "2" && query[1] === "1"){
console.log(que1.shift());
} else if(query[0] === "2" && query[1] === "2"){
console.log(que2.shift());
}
- クエリタイプが「2」なら取り出し操作
shift()で先頭から取り出して出力
5. サイズ確認
else {
console.log(que1.length, que2.length);
}
両方のキューのサイズを出力します。
実行例
入力:
8
1 1 3
1 2 5
1 1 7
2 1
3
2 2
1 2 9
3
実行の流れ:
// 初期状態
que1 = []
que2 = []
// クエリ1: "1 1 3" → que1に3を追加
que1.push("3")
que1 = [3]
// クエリ2: "1 2 5" → que2に5を追加
que2.push("5")
que2 = [5]
// クエリ3: "1 1 7" → que1に7を追加
que1.push("7")
que1 = [3, 7]
// クエリ4: "2 1" → que1から取り出す
出力: 3 ← shift()の結果(最初に入れた3)
que1 = [7]
// クエリ5: "3" → サイズ確認
出力: 1 1
que1 = [7], que2 = [5]
// クエリ6: "2 2" → que2から取り出す
出力: 5
que2 = []
// クエリ7: "1 2 9" → que2に9を追加
que2.push("9")
que2 = [9]
// クエリ8: "3" → サイズ確認
出力: 1 1
que1 = [7], que2 = [9]
最終出力:
3
1 1
5
1 1
キュー実装のパフォーマンスに関する注意
shift()の問題点
実は、JavaScriptの shift() はO(n)の計算量がかかります。
なぜ遅い?
let queue = [1, 2, 3, 4, 5];
queue.shift(); // 1を削除
// 内部的な処理:
// [_, 2, 3, 4, 5] ← 先頭を削除
// [2, 3, 4, 5] ← 全要素を前にずらす(O(n))
先頭を削除すると、残りの全要素を1つずつ前にずらす必要があるため、要素数に比例した時間がかかります。
キュー実装のポイント
1. push/shiftの組み合わせ
// ✅ キューの標準的な実装
queue.push(data); // 末尾に追加
queue.shift(); // 先頭から取り出し
2. 空のキューからshiftしない
let queue = [];
// ❌ 空の状態でshift
let data = queue.shift(); // undefined
// ✅ チェックしてからshift
if(queue.length > 0){
let data = queue.shift();
}
3. 先頭の確認
let queue = [1, 2, 3];
// 先頭を見る(削除しない)
let front = queue[0]; // 1
比較表
| 特徴 | スタック(Stack) | キュー(Queue) |
|---|---|---|
| データ構造 | LIFO(後入れ先出し) | FIFO(先入れ先出し) |
| 追加 | push() | push() |
| 取り出し | pop() | shift() |
| 取り出す場所 | 末尾(上) | 先頭(前) |
| イメージ | ブロックの積み重ね | カフェの行列 |
選び方:
- 最新のものから処理したい → スタック
- 古いものから順番に処理したい → キュー
まとめ
今回、paizaの「2つのキュー」を通して学んだポイント:
- キューはFIFO(先入れ先出し)のデータ構造
- レジの行列をイメージすると理解しやすい
- JavaScriptでは配列の push/shift で簡単に実装できる
- スタックとは逆の動き(最初に入れたものが最初に出る)
- shift()は遅いが、通常の問題では問題ない
キューの基本操作まとめ
| 操作 | メソッド | 説明 | 計算量 |
|---|---|---|---|
| 追加 | push(data) | キューの末尾に追加 | O(1) |
| 取り出し | shift() | キューの先頭から取り出す | O(n) |
| 確認 | queue[0] | 先頭を見る(削除しない) | O(1) |
| サイズ | queue.length | キュー内の要素数 | O(1) |
| 空チェック | queue.length === 0 | キューが空か確認 | O(1) |
paizaでキューを学んで感じたこと:
最初は「配列と何が違うの?」と思っていましたが、実際に問題を解いてみると、「先頭と末尾だけ触る」という制約が理解できました。
レジで並ぶときも、途中から割り込んだり、列の真ん中の人を先に会計したりしませんよね。先に並んだ人から順番に進む、というルールを守ることで、公平で分かりやすい仕組みになっています。
プログラムでも同じで、この制約があることで、データの流れが明確になり、バグが起きにくくなるんだと実感しました。
スタックとキューは、データ構造の基本中の基本です。
今回学んだ内容を使えば、様々なアルゴリズム問題が解けるようになります。特に、探索アルゴリズム(DFS/BFS)ではスタックとキューの理解が必須です。
次回は、これらのデータ構造を使った応用的なアルゴリズムに挑戦していきたいと思います!
関連記事:
この記事は paizaラーニング の学習記録です。

コメント